Yandex Blog
How Yandex Stores User Data
There has been a lot of speculation in the media recently on how we handle user data. We wanted to take this chance to clarify how Yandex works with data generally, and how AppMetrica works in particular.
Our commitment to user privacy
For over twenty years, Yandex has served millions of users, working to maintain their trust through our commitment to protecting their privacy and data security online. Our detailed Privacy Policy helps users understand more about what data we collect, how this data is used to improve our services, who has access to that data, and how users can control it.
Yandex takes data security extremely seriously and follows rigorous data protection rules to ensure our users’ data is secure and their privacy is protected. Our services are assessed according to the Data Protection Impact Assessment (DPIA) procedure. We regularly undergo audit procedures and receive certification of a high level of information security and customer data protection, including ISO/IEC 27001/27017/27018, SOC 2/3, PCI DSS etc. In particular, AppMetrica, our mobile analytics service, itself is certified ISO/IEC 27001 compliant.
AppMetrica
AppMetrica is a mobile app analytics solution that helps mobile developers improve the in-app experience by identifying and fixing errors, optimizing advertising settings and building marketing strategies based on in-app user performance. It operates in the same way as international peers such as Google Firebase, Flurry by Yahoo, Adjust and AppsFlyer. In short, AppMetrica is a tool that app developers use deliberately for its core analytical functionality.
AppMetrica doesn’t collect any data on its own – we can only receive the information the app developer shares with the tool to be automatically analyzed and compiled into a report. The app also needs to receive user consent required by the mobile operating systems (OSes), since there is no technical possibility for us to obtain it ourselves. We inform app developers about the functioning of AppMetrica and they are obliged, if required by law, to get consent from their users.
Thus, as per GDPR, app developers have to specifically accept the Data Processing Agreement upon setting up AppMetrica and are expressly offered to mask IP addresses of EU users. Our instructions indicate that it’s the app owner's duty to make sure that the app's Privacy Policy clearly states that it’s using AppMetrica.
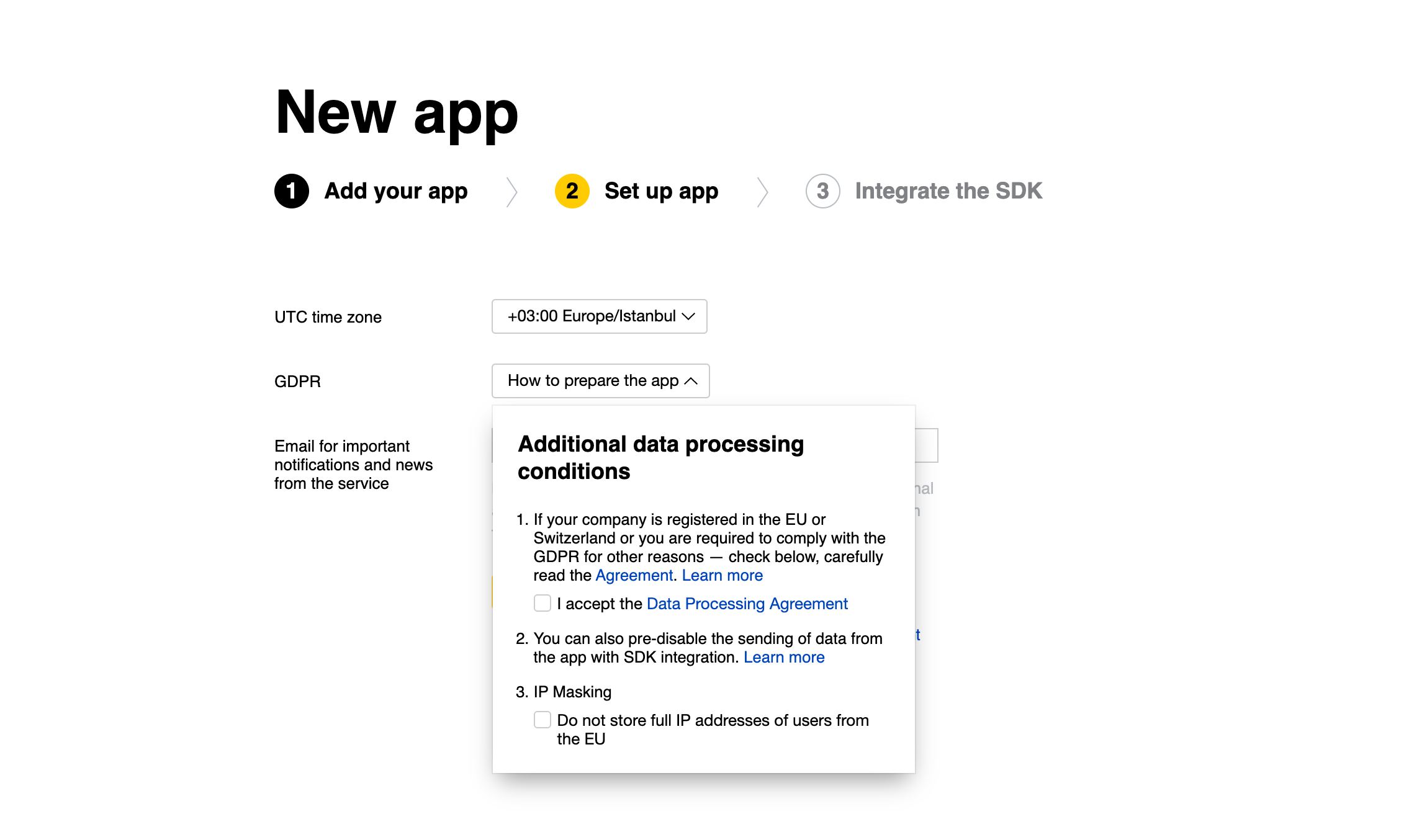
Setting up AppMetrica
App developers themselves determine the type and amount of data they want to analyze. We do not collect any sensitive user data concerning users’ names, addresses, phone numbers, payment details, personal ID data or any other sensitive personal details that the user shares with the application. We also do not and cannot collect data about what users do outside the app. AppMetrica is constantly monitored and assessed by Apple and Google for compliance with App Store and Play Store moderation policies, which set high standards for user data protection.
Data received by AppMetrica from app developers is non-personalized, very limited, and contains information on the device, network and IP address (if not masked by the app developer). AppMetrica reports display technical data that is of high value only to the application developers – such as the device model, application version, operating system version, etc. They also show information on the users’ behavior in the application, for instance, time spent, application crashes, in-app purchases, etc. Such information is crucial for improving the user experience — it helps to identify errors and promptly warn developers about them, send notifications to users, optimize advertising settings and, finally, to analyze which products are in highest demand based on purchasing statistics.
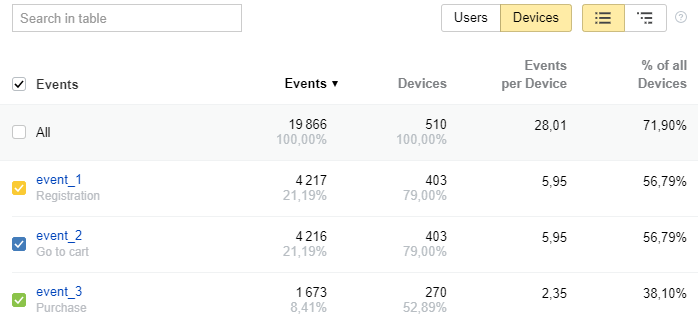
Example of a report in AppMetrica
Data storage in Russia
We make no secret of our Russian roots. Our approach to data is in line with other major technology companies around the world. We work in full compliance with international and local laws. Data received from app developers is stored in a distributed storage platform both in Finland and in Russia, as stated clearly in our Privacy Policy. The idea that we ‘secretly’ send this data to Russia is simply wrong. Our Privacy Policy has always been publicly available for anyone.
Our job is to inform developers regarding AppMetrica’s data processing terms and they are obliged, if required by law, to get consent from their users and inform them about the fact that the data is stored in Russia. In our instructions for app developers we even provide a sample alert message that clearly states that the information will be transferred to Yandex and stored on Yandex’s servers in the EU and the Russian Federation. Again, this is compliant with all international laws and regulations regarding data storage.

What does it mean for users? Regardless of where data is stored, our principles for data privacy and security are equally rigorous. We take any government request for access to information extremely seriously (be it in Russia or any other country) and follow the same principles whether it’s coming from the Russian government, or international bodies such as Interpol.
We have never given out any information on users of any apps with AppMetrica installed on them, nor have we ever been asked to.
Still, if we ever were to receive such a request, we have a very strict internal process to identify the legitimacy of the request. Yandex only considers those requests that have been lodged by an authorized entity in accordance with the laws and the due process, and only provides the amount of information that is strictly required in order to fulfill the request. Any requests that fail to comply with all relevant procedural and legal requirements are turned down.
We are fully transparent about all data requests we satisfy, and we publish a detailed report on a regular basis. Please see our transparency report at https://yandex.com/company/privacy/transparencyreport.
Here at Yandex, we take any accusations about possible privacy misconducts close to heart and we are ready to be audited by any international audit companies on the legality of our privacy policies and data collection practices.
Helping to Save Endangered Language with Yandex Translate
Spoken across some of the world’s northernmost territories, Yakut is an indigenous language with fewer than half a million people currently using it in their everyday life. Listed as one of the endangered languages, Yakut is risking disappearing off the face of the earth and taking a unique culture and original group identity with it.
Thanks to the passion, dedication and enthusiasm of one single individual, as well as support from the Yandex team, two years ago Yakut was added to Yandex’s automated translation service Yandex Translate, and this year we have released a film telling the story of this journey.
Yandex’s translation technology not only bridges gaps and breaks barriers, it also contributes to the preservation and promotion of languages and cultures. It offers automated translation between over a hundred languages, including rare, such as Hill Mari, fictional, such as Elvish, and even symbolic, such as Emoji.
For its translating capabilities, Yandex Translate’s technology relies on a large number of examples on the one hand, and neural networks on the other. Despite its mind-blowingly complex structure that lets Yandex Translate’s neural model learn a new language on its own, it still needs to learn from a large number of so-called ‘parallel’ examples, equivalent pieces of text in two different languages.
The problem with the Yakut language was that there was simply not enough written text for a language model to learn from. Inspired by the grassroot enthusiasm of a group of the Yakut people and with their hands-on contribution, Yandex engineers developed a way for their neural model to learn this disappearing language.
This film is about how technology can help people in their collective effort to support a vulnerable language and culture. You can now watch here or on YouTube (please, enable the English subtitles in Settings).
Yet another Conference 2021: Turning a New Page
Yet another Conference (YaC), our annual conference on technology and innovation since 2010, continues last year’s Yet another Conversation with Yet another Chapter. This event lets us sum up our efforts, share our achievements and look at our past, present and future.
Some of the most impactful launches, events and results of the year are reflected upon by the people who stand behind them in the new YaC film. In addition to talking about innovative voiceover video translation technology or using augmented reality while shopping for home appliances online, Yandex managers and engineers reveal how new ideas are born and how they are turned into products.

You will see cutting-edge energy-efficient data centers, supercomputers, a closed testing track and an engineering center for self-driving cars, a project for a robotaxi service in Moscow, and a lab where Yandex’s virtual assistant Alice lives. You will also find out what happened when Yandex executives put themselves in the shoes of a taxi driver, a courier and a personal shopper.

Looking ahead, the new product announcements and premieres of this year include the second generation of the Yandex Station smart speaker. The updated device has an improved sound quality and a new design. It is fully compatible with other smart home devices, all of which can be controlled via a smart home app. The new Yandex Station will hit the market before June 2022.

Other product updates include Alice’s new skills and features. Yandex’s smart virtual assistant has learned to whisper and make stories. Alice uses a YaLM-family language model, trained on Yandex supercomputers, to make up a story on request. She composes an original storyline by asking questions and using cues from the person talking to her. You can watch this happen in real time at the end of the film. The storymaking feature will be rolled out on all Alice-enabled devices at the end of this month.

The people and the stories in YaC’s new chapter are introduced by the blogger and journalist Irina Shikhman. She talks about Yandex, its products and services, to Tigran Khudaverdyan, Yandex Deputy CEO, and finds out the answers to some of the most popular questions, such as how the company uses personal data and what affects the price of a Yandex Taxi ride. Other important questions answered in the YaC 2021 film include how Google is used at Yandex, what a cat can do to a Yandex Station, and whether thirty Alices can tell the time at the same time.
Watch YaC 2021 to find out more.
Yandex Supercomputers Top Entries from Russia and Eastern Europe Among World’s Most Powerful Computing Systems
Three Yandex supercomputers rank ahead of other entries from Russia and Eastern Europe in the TOP500 list, with the company’s most powerful supercomputer Chervonenkis ranking in the top 20 globally
Yandex’s most powerful supercomputer ranks 19th in the global TOP500, showing the best results for high-performance computing systems in Russia and Eastern Europe. Named after one of the greatest machine learning theorists, Alexey Chervonenkis, Yandex’s fastest supercomputer has 199 nodes and produces 21.53 petaflops, that is, 21.53 quadrillion floating-point operations per second.
The other two Yandex TOP500 entries, also named after Russia’s great contributors to computer science and machine learning, Alexander Galushkin and Alexey Lyapunov, ranked 36th and 40th, with 16.02 and 12.81 petaflops, respectively. These supercomputers are also second and third fastest in Russia.
Lyapunov was launched in December 2020, while Chervonenkis and Galushkin started operating in June 2021.

Yandex supercomputers are used for training neural network models with billions of parameters. Such models are so complex that to train them, a supercomputer must work at peak performance for days, and sometimes even weeks. Although they aren’t easy to train, these neural networks help Yandex offer life-improving products and services for its users. Neural networks trained on Yandex’s supercomputers enable more accurate and faster translation for text, image and video content on Yandex.Translate. Thanks to these networks, customers can see relevant ads served by Yandex.Direct. The YaLM language models, also powered by these supercomputers, are used for generating and ranking instant search results, as well as for supporting human-like conversational abilities of Yandex’s AI-based virtual assistant Alice.
The Chervonenkis and Lyapunov high-performance computing systems are located in Yandex’s data center in Sasovo, while the Galushkin supercomputer is in Vladimir. All the three Yandex supercomputers are based on AMD EPYC processors and NVIDIA A100 graphics accelerators.
Each system includes over a hundred servers, or nodes, connected by a high-speed Infiniband HDR network. The computing nodes in the Chervonenkis and Galushkin supercomputers feature an optimized heat removing system designed by Yandex to use less power for cooling the servers.
The TOP500 global supercomputer ranking has been published in June and November each year since 1993. The performance of supercomputers for this ranking is evaluated based on the results of the LINPACK test, which measures how fast a computer can solve a system of linear equations. The top spot in the November 2021 TOP500 belongs to Supercomputer Fugaku from Japan. Yandex debuts in the ranking in the top three places among Russia's only five entires in the top 100.
Yandex Announces Its Second Conference on Education on November 10
The second Yandex conference on education, YaC/e, will take place online on November 10.
Education experts, practitioners and edtech market leaders will meet on the Yandex platform to talk about current trends in education and share their experiences. This event, designed for teachers, school and university administrations, parents, educational project founders, researchers and anyone interested in education, is an excellent opportunity for everyone to engage and learn.
This year’s conference will be hosted by Andrey Sebrant, Director of Strategic Marketing at Yandex, and Natalia Tsarevskaya-Dyakina, the founder and CEO of the edtech accelerator ED2.
Speakers at the YaC/e conference speakers will include leading education experts and edtech market players at the forefront of cutting-edge educational technologies, and those who fully understand learners’ needs and challenges. Their focus this year will be on:
- how people's desire to learn, create educational products or invest in education will affects the economy of the future;
- how people choose a profession, what they expect from their education and how the demand for new courses, techniques and tools is shaping the market; and
- the variety of training formats currently available on the market, including mathematical education that offers foundational skills for working in IT.
Other speakers at the conference will include the science journalist and author Asya Kazantseva; the head of Yandex’s digital education platform, Practicum, Misha Yanovich; Skypro Managing Partner Alexander Laryanovsky; and Barbara Oakley, Professor of Engineering Sciences at the University of Auckland and a co-author of the self-help book and study guide for students Learning How to Learn.
Participation in the YaC/e conference is free and does not require registration.
Save the date and join the live event online on November 10, 09:30 GMT+3!
The first Yandex conference on education, YaC/ed, took place in Moscow in 2020. It focused on the role of technology and its accessibility in education. Its program included more than 30 talks and sessions by over 70 speakers from the leading businesses and top universities. The live event was watched by more than 30,000 viewers.
Yandex Employees Win International Collegiate Programming Contest
Valeriya Ryabchikova, a junior software developer with Yandex’s e-commerce platform Yandex.Market, has won the 44th International Collegiate Programming Contest (ICPC) in Moscow as part of a team of three representing Nizhny Novgorod University.

The silver medal was taken by a three-member team that included another Yandex employee, Aleksander Kernozhitsky, a student at Belarusian State University. At Yandex, Aleksander is working on distributed analytical tools within the company’s Search, Advertising and Cloud Business Group. His team was trained by a seasoned computer programming coach and international Olympiad expert, Aleksey Tolstikov, who heads the Belarusian branch of the Yandex School of Data Analysis in Minsk.
The International Collegiate Programming Contest is the world’s largest and most prestigious competition in sports programming for university teams. Running annually since 1977, this is like the Olympic Games in algorithmic problem-solving for university students, which attracts thousands of participants from over a hundred countries. Every year they gather for a series of final rounds to solve as many non-trivial mathematical problems—presented as real-life situations—as they can as quickly as possible. This year’s problems included calculating the budget for speed-limit signs in a newly built town, finding the best spot for photographing St Basil’s Cathedral in Moscow, modeling a landscape and simplifying the reading of a genetic code.

The ICPC gives young mathematicians an opportunity to shine, while companies and research institutions can discover new talent.
19 out of 66 contestants on 22 teams representing the Northern Eurasia region at the ICPC this year were current Yandex employees, while a further eight participants previously interned at Yandex.
17 participating Yandex employees reached the ICPC 2020 finals.
With a strong background in competitive programming, Yandex provided technology support for the ICPC 2020 finals in Moscow. Yandex’s history in sports programming includes its own Yandex Cup competition, which has been running since 2011 (previously as Yandex.Algorithm). We will continue to support competitions and events that promote mathematics and its applications in real life to advance science and technology and improve quality of life for everyone.
We wish the winners, the finalists, their coaches and teams all the best in their future endeavors!
Yandex Launches Ilya Segalovich Foundation to Support Education in Maths and IT
Today we are launching the Ilya Segalovich Foundation. This new Yandex project bearing the name of the company’s co-founder Ilya Segalovich will support organizations and public initiatives engaged in the development of affordable high-quality education in mathematics and IT. The Foundation will also include all non-profit educational projects of Yandex.
"Today, on September 13, the birthday of Ilya Segalovich, we are announcing the Foundation that will carry his name. Ilya was passionate about what he did, genuinely loved people, and helped those who were in need. For many, he was a mentor and a role model, a teacher in the best sense of the word. Acting in the spirit of Ilya, the Foundation will focus on creating educational solutions that will improve the life of individuals, as well as society overall. Strong education gives everyone an opportunity to realize their potential and feel confident in the future," comments Elena Bunina, CEO of Yandex in Russia.
The key objectives of the Ilya Segalovich Foundation are to:
● improve access to modern education in IT and mathematics;
● develop education through open data, methods and technologies;
● support teachers and professional community;
● support projects that foster public interest in knowledge, science and culture.
In addition to developing its own projects, the Ilya Segalovich Foundation will support other organizations and public initiatives through grants. The total amount of grants available to potential recipients in 2022 is 250 million rubles ($3.5 million). The applicants will be evaluated by the Foundation's panel of experts, which includes education specialists, well-known public figures, and Yandex representatives. The members of the panel, as well as the grant programs, will be announced at the Yandex conference on education, YaC/e, on November 10.

Yandex has been developing educational projects for 15 years. Our educational effort has benefitted about 6 million people: schoolchildren, students, beginner specialists and experienced teachers. As of today, almost 2 million school children used Yandex.Textbook for their studies, more than 1,000 students have graduated from the Yandex School of Data Analysis, with over 6,500 children graduating from the Yandex Academy Lyceum, while more than 1,500 students enroll in Yandex programs at universities every year.
The Ilya Segalovich Award in Computer Science has been honoring outstanding academic achievement and research since 2019, with dozens of postgraduate students and academicians having received more than 30 million rubles ($400,000) in grants. The Ilya Segalovich Scholarship is a stipend supporting talented Computer Science students at the Higher School of Economics in Moscow.
In 2019, Yandex launched an initiative for the development of education through technology. Within its framework, the company pledged to invest 5 billion rubles ($70 million) until the end of 2023 to expand its free educational projects in Russia. This work will now continue within the Ilya Segalovich Foundation and will be reinforced with further investment.
Ilya Segalovich (1964-2013) is a co-founder and CTO of Yandex; the author of the first version of the Yandex search engine and creator of the word ‘Yandex’; co-organizer and supporter of the Maria's Children Art Rehabilitation Center for orphans and children with special needs.
Yandex Rolls Out New Search Update
Yandex has updated its search engine to integrate a family of generative neural networks, plus more than 2,100 other improvements.
As a result, Yandex users gain new features and upgrades including video timestamp responses to search queries, more detailed quick answers to a greater number of queries, improved object recognition in real time, and the ability to view a summary of customer feedback.
Most of the improvements are based on deep neural networks trained on massive volumes of data. The group of generative algorithms introduced in this update is called Yet another Language Model (YaML), they are trained on terabytes of data, and use up to 13 billion parameters to understand natural language and generate responses in Russian. YaLM is used to produce up to 17% of the interactive replies for Yandex’s intelligent voice assistant Alice. It also generates captions for rich search results and determines the ranking of quick answers on Yandex Search.
Some notable improvements from the search engine update include:
Video Timestamp Results
Now, in response to a search query such as how to cook a tuna steak, Yandex users are offered a video that starts exactly from the moment this specific demonstration happens, skipping any irrelevant information. Currently available on mobile devices and coming to desktop in the near future, this feature works best for ‘how to’ queries and video manuals that teach viewers, for example, how to wash a dog or learn to skate.
Quick Answers
Yandex Search now responds with quick answers to more user queries across more topics, and also offers more details related to each query. In addition to the information that explains how to train a horse in Minecraft, for instance, or shows the hidden features in iOS, Yandex Search users can now view responses to related queries made by other users. For example, when looking for information about how to start your own business, the Yandex Search users will be offered additional information such as legal requirements for starting a business or how much it may cost. Internet users currently view more than 130 million unique quick answers on Yandex Search each month.
Smart Camera
The Smart Camera feature in the Yandex App and Yandex Browser provides mobile users with instant information about objects in real life, including the price of commercially available items and where to buy them. This feature can also be used for instant translation between 45 languages, as well as document scanning and editing. The update also improved Smart Camera object recognition and information retrieval – it now identifies objects in real life and serves up information about them five times better.
Customer Feedback Summary
To help people make a decision about choosing a cafe, restaurant, hotel, shop, or other businesses or organizations – and save them the time it takes to read through hundreds of customer reviews – Yandex now provides an automatically generated customer satisfaction rating scale right in the search results. In response to a query about a restaurant, the user will now instantly see an overview of how other visitors rated their food or service.
Automated Caller ID and Blocking
Yandex App users on iOS and Android devices can now enable automatic caller ID to identify incoming phone calls and filter unwanted callers. Automated blocking or muting for unsolicited or fraudulent calls is scheduled for release next month.
The new Yandex update streamlines users’ search experience, making it easier for them to navigate the online and offline world.
Third Ilya Segalovich Award Honors New Winners
The third annual Ilya Segalovich Award ceremony presented each of the six winners with one million rubles to recognize their outstanding contributions to applied and theoretical research in computer science and related fields.
Yandex established the honor, named after its co-founder Ilya Segalovich, in 2019. Open to young researchers and academics in Russia, Belarus and Kazakhstan, the Award recognizes new talent and outstanding work in research supervision in the key areas of Yandex interest and has already supported more than two dozen recipients. This year’s event took place in Moscow at the end of last month and honored four young researchers and two academics. They were recognized alongside the 2020 winners, who were unable to receive their awards in person due to Covid restrictions last year. Two of this year’s winners are repeat honorees.
The topics of research honored by the Ilya Segalovich award this year include recurrent neural networks and recurrent learning, online machine learning, generative models and aggregating algorithms, optimization methods, agent-based systems and reinforcement learning, computer vision and artificial intelligence.
In addition to the monetary prize, the Award covers travelling expenses and fees to attend any conference of the winner’s choice. Each winner is also provided with a credit for Yandex’s cloud service Yandex DataSphere and its data labeling platform Toloka.
The Ilya Segalovich Award was created to not only reward young scientists for their achievements, but also to provide them with the opportunity to continue their academic research.
Yandex supports education and research in a number of ways, including through its Yandex School of Data Analysis, collaborations with universities, and its Educational Initiative. Launched in 2019, the Educational Initiative trains IT specialists, enables people to participate in the digital economy, equips school teachers with technology skills and helps them engage with their students. The ultimate goal of the Initiative is to support science, foster a knowledge society, and improve education through technology.
Yandex Browser Gives Users Control Over Third-Party Cookies
Yandex has rolled out a feature that automatically blocks unauthorized third-party cookies and lets users manage their third-party cookies through a simple dashboard built into the Yandex Browser. The new feature enhances user privacy and grants users control over who they share their data with, while still allowing advertisers to reach their potential customer
Yandex Browser, first launched in 2012, is now available in 14 languages on all digital platforms and has a monthly audience of 35 million users on desktop and 37 million mobile users worldwide. The YTP feature is available on desktop as well as on mobile for Android devices.
The technology is called Your Tracking Protection (YTP) and it only allows third-party cookies from websites that are deemed trusted. These sites alone can show relevant ads or use features provided by other parties, such as a sharing button or chat functionality. Third-party cookies from websites that users have never visited before are blocked by default. Previously visited websites are considered trusted though the user is able to change this setting at any time. Information about YTP can be viewed directly in the browser.
Yandex Browser users will also be able to see which third-party trackers have been blocked or allowed automatically on any given website and choose to block or unblock any of them. The new feature is easy to use and gives users a full and transparent view of third-party cookies running on each website.
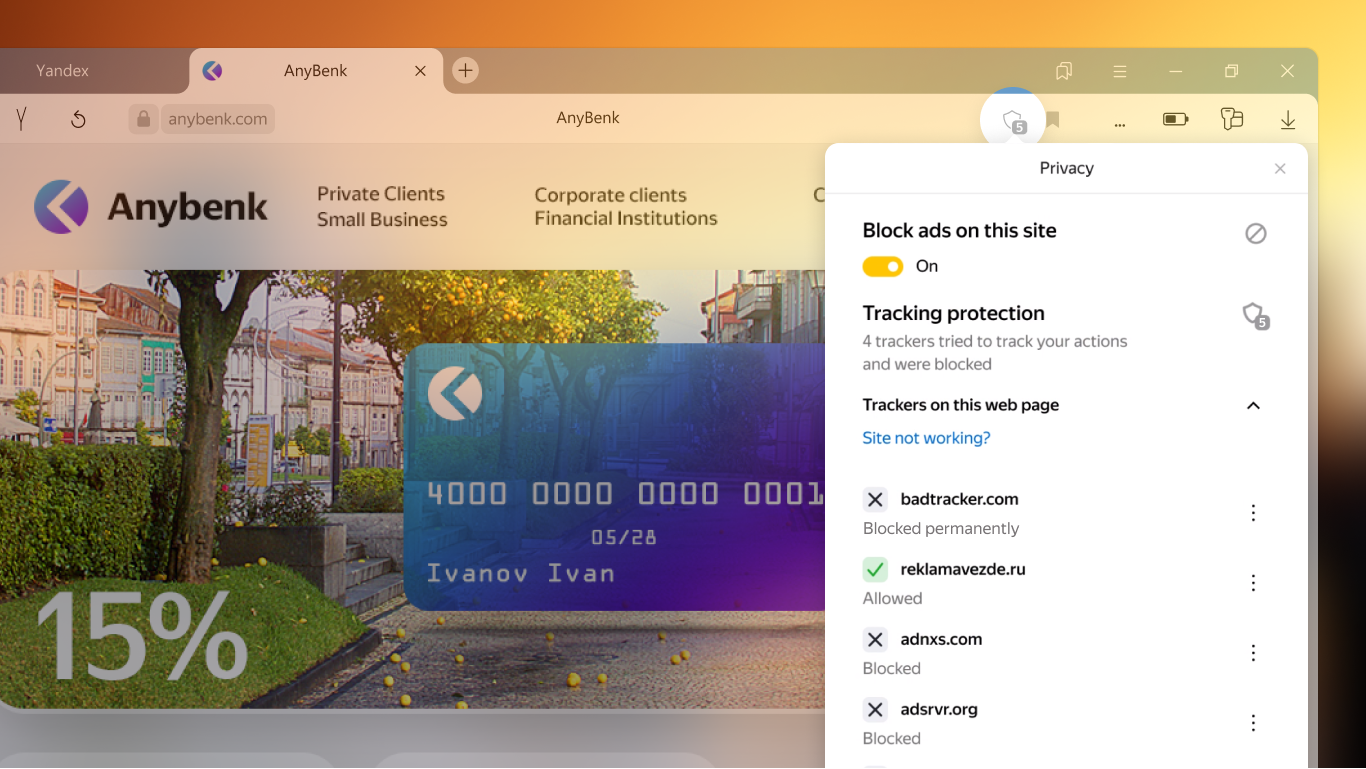
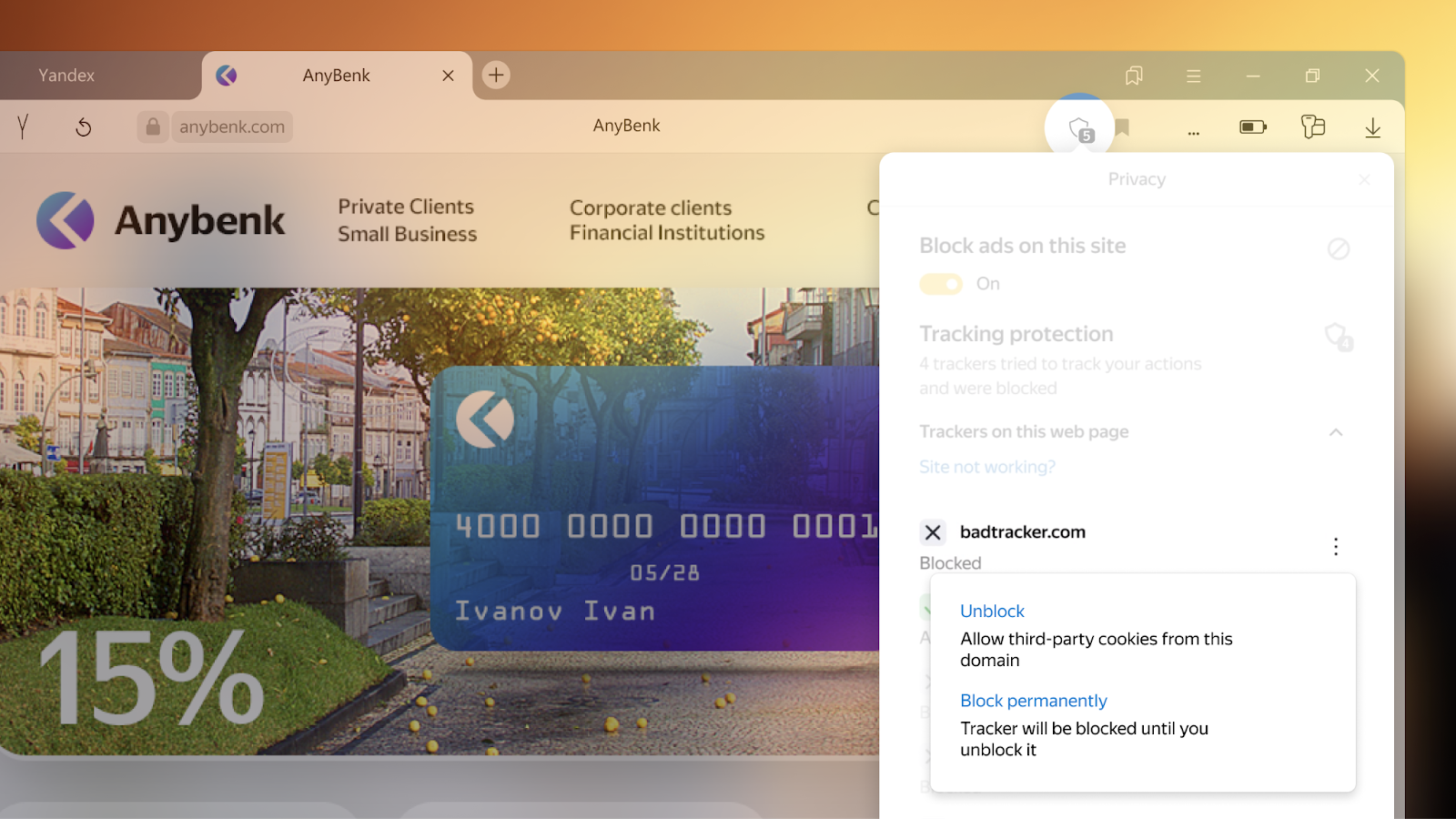
At Yandex, we believe in creating solutions that benefit content creators and advertisers without compromising user privacy. Web users should be able to see who can access their information and manage how it is used. Unauthorized sharing of data should be eliminated, but a blanket ban on all third-party cookies is a measure that may affect the whole ecosystem including users, publishers, websites and advertisers. Total blocking of third-party cookies will make it harder for advertisers to target their desired audiences, while web users will be exposed to irrelevant ads. They may also be unable to access multiple websites with the same login or share web content to social networks. The YTP technology strikes a balance between complete blocking of all third-party cookies, providing users with a safe and personal internet experience, while allowing advertisers to engage with potential customers.
In addition to launching the YTP technology in Yandex Browser, we are also providing clients on our advertising platform with targeting opportunities that do not rely on third-party data, such as context-based targeting.
We will continue to develop technologies and advertising solutions to ensure that advertisers and web users can interact safely and efficiently.